 메프도의 요약노트
메프도의 요약노트
굉장히 독창적인 결과물을 보여주었던
3D-GANTex 구동 이후 대안을 찾기위해
가장 유명한 Deep3DFaceReconstruction을 구동해보았다.
Microsoft의 Deep3DFaceReconstruction의 비공식 구현체이다.
원래의 TensorFlow 구현을 PyTorch로 변환한 버전이다.
나의 고초가 담긴 구현 코드 정리본
[Research] Deep3DFaceRecon_pytorch 구동 및 분석 · Issue #22 · oMFDOo/OpenSourceIssue
Deep3DFaceRecon_pytorch 구동 및 분석 : 심층 학습 기반 3D 얼굴 재구성을 수행. 단일 이미지 입력만으로 고품질 3D 얼굴 메쉬와 텍스처를 생성 주요 특징 단일 이미지 기반 3D 재구성 단일 2D 얼굴 이미지
github.com
Deep3DFaceRecon_pytorch 개요
: 심층 학습 기반 3D 얼굴 재구성을 수행. 단일 이미지 입력만으로 고품질 3D 얼굴 메쉬와 텍스처를 생성
주요 특징
- 단일 이미지 기반 3D 재구성
- 단일 2D 얼굴 이미지를 입력받아 3D 얼굴의 메쉬와 텍스처를 생성
- 입력 이미지에서 얼굴 모양, 표정, 피부 텍스처까지 정확히 복원 가능
- 심층 학습 및 합성 데이터 활용
- 대규모 합성 및 실제 데이터로 학습된 심층 신경망을 기반으로 동작.
- 3DMM(3D Morphable Model)을 기반으로 얼굴 형상을 모델링
- Pretrained 모델 제공
- 학습된 가중치와 설정 파일을 제공하여 즉시 사용 가능.
- 기존 얼굴 인식 및 표현 작업의 백엔드로 활용 가능
기술적 구성 요소
- 3DMM 파라미터 추출
- 얼굴의 모양, 표정, 알베도(albedo) 등의 파라미터를 추출하여 3DMM 형식으로 변환.
- GAN 기반 텍스처 복원
- 이미지 기반에서 생성한 텍스처를 더욱 자연스럽게 보정 및 향상.
- Deep3DFaceRecon_pytorch는 이 과정에서 픽셀 정확도를 높이는 기술을 적용.
기본 환경 설정 : (1)
1) Repository clone
: 코드를 받아온다.
git clone https://github.com/sicxu/Deep3DFaceRecon_pytorch.git
cd Deep3DFaceRecon_pytorch
2) 가상환경 구성
conda env create -f environment.yml -n Deep3DFaceRecon
2-1) 가상환경 구성 시 아래와 같은 오류 발생
: pip 결여 (이 문제의 해결로 같은 문제를 겪은 이에게 도움을 줄 수 있었다. 뿌듯 😊)
Pip subprocess error:
/home/azureuser/anaconda3/envs/Deep3DFaceRecon/bin/python: No module named pip
failed
CondaEnvException: Pip failed
2-2) pip 설치
: 현재 environment.yml에 의해서 Python 3.6.15 버전을 이용중
curl https://bootstrap.pypa.io/pip/3.6/get-pip.py -o get-pip.py
python get-pip.py
pip --version
2-3) pip 결여로 실패한 종속성 다운로드
pip install matplotlib==2.2.5 \
opencv-python==3.4.9.33 \
tensorboard==1.15.0 \
tensorflow==1.15.0 \
kornia==0.5.5 \
dominate==2.6.0 \
trimesh==3.9.20
기본 환경 설정 : (2)
1) Repository clone
: 코드를 받아온다. 항상 그렇듯 가끔 문서가 오기입될 때가 있다. 이런 거 개선 요청 해주면 받아주나? ㅎㅎ
❗ 사진의 경로는 틀렸다. Deep3DFaceRecon_pytorch 경로 내부에서 clone 받아야한다.
git clone -b v0.3.0 https://github.com/NVlabs/nvdiffrast+ 싶었으나 역시 이미 누가 건의했다.
2) pip install .
pip install .
기본 환경 설정 : (3)
1) 경로 이동
cd .. # ./Deep3DFaceRecon_pytorch
2) Repository clone
git clone https://github.com/deepinsight/insightface.git
3) 모델 파일 복사
cp -r ./insightface/recognition/arcface_torch ./models/
사전 학습 모델 이용 (1)
1) Basel의 01_MorphableModel.mat 파일 획득 및 삽입
1-1) 링크를 통해 데이터 요청
1-2) 요청 완료된 모습
1-3) 그럼 이런 느낌으로 작성한 메일로 파일이 보내짐
1-4) 다운 받은 BaselFaceModel.tgz파일의 압축 해제를 위해 7-ZIP을 이용함
1-5) Deep3DFaceRecon_pytorch/BFM/경로에 01_MorphableModel.mat 삽입
2) Guo et al의 Exp_Pca.bin 다운로드
: Guo et al.에서 제공하는 Expression Basis도 이용한다.
2-1) google drive 링크를 통해 Exp_Pca.bin 다운로드 할 수 있다.
2-2) Deep3DFaceRecon_pytorch/BFM/경로에 Exp_Pca.bin 삽입
사전 학습 모델 이용 (2)
1) 사전 학습 모델 다운로드
CelebA, LFW, 300WLP, IJB-A, LS3D-W, FFHQ 데이터셋을 조합해 학습한 모델을 제공함.
링크를 통해 사전 학습된 모델 epoch_20.pth을 다운로드
2) 모델 배치
모델 이름으로 파일명을 짓는 것이 모호했는데 여기에서 힌트를 얻었다.checkpoints\shd 경로에 epoch_20.pth파일을 배치한다.
사용자 이미지를 이용한 테스트
: 테스트를 위해서는 랜드마크 정보가 있어야 하는데, 임시로 제공 데이터를 사용하겠다.
제공 이미지 기반 테스트
python test.py --name=shd --epoch=20 --img_folder=./datasets/examples
혹여나 여기서 에러가 난다면 아래를 참조할 수 있다.
[Error] undefined symbol: iJIT_IsProfilingActive
[Error] CUDA error: no kernel image is available for execution on the device
두 번째 글에는 설정하며 겪은 에러들이 여러 개 들어있다. 참고하기 좋을 것 같따.
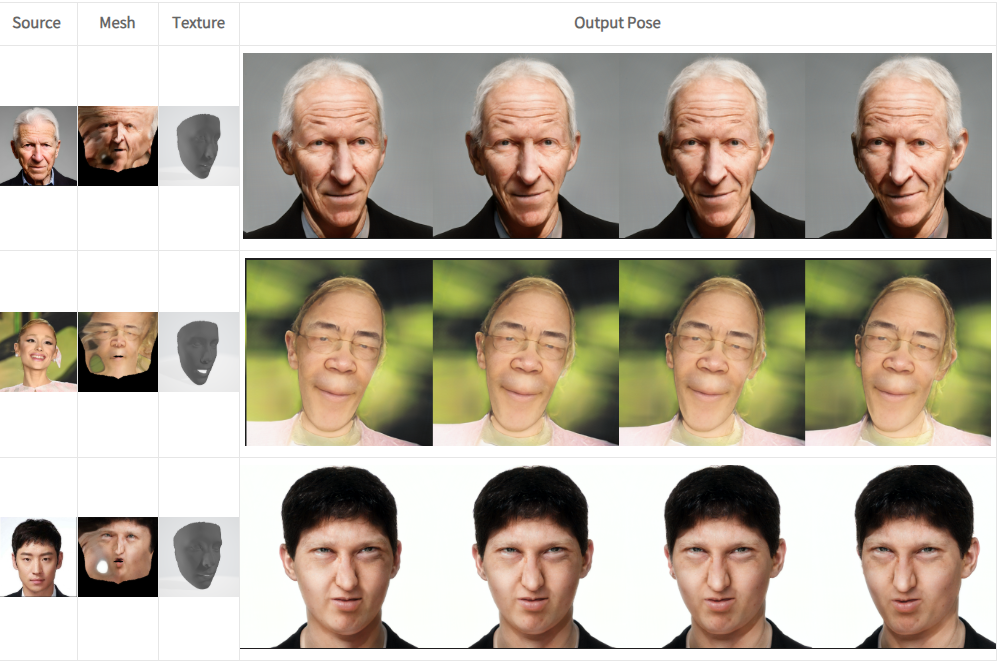
결과 도출
| Input | Overview | Mesh |
|---|---|---|
아직 따로 텍스처를 뽑아보진 않았지만 다양한 환경에도 강력하게 잘 버틴다.
해당 논문에서 언급한 대로 모자, 머리카락으로 인해 얼굴이 가려지거나,
강한 화장으로 이목구비를 강력하게 강조했을 때에도 괜찮은 결과물이 도출되었다.
생성된 텍스쳐의 화질은 조금 낮아보여, 업스케일링 혹은 다른 방향으로의 화질 개선이 추가된다면 훌륭할 것이다.
또한 짓고있는 표정 그대로 메시가 생성되게 되는데, 이 또한 고려할 문제사항으로 꼽힌다.


눈의 총기를 잃은 것이 아련하다.
하지만 이는 의도한 것이 맞다.
이마, 눈 등에 위치한 반사광 경우에 대해 제거한다.
이를 위해서 이곳에서는 구면 조화함수를 기반하여 모든 빛을 적분 하는 것이 아닌
최적화된 광원 제거 기법을 도입하였다.

또한 나는 앞머리 + 헬멧 + 안경 + 진한 화장의 콜라보로 얼굴을 뜨기 쉽지 않은 상태인데
이 또한 처리를 위해 급진적 변화가 발생하는 부분에 대한 패널티를 크게 먹여 학습하였다.
논문 예제에는 스카우터같이 생긴 큰 안경으로 얼굴을 완전히 가린 모습에도 멋있게 생성해준다.


내 사진으로 돌려보는 법
나의 사진을 이용해 코드를 구동하고자 한다면,
내 이미지 + 랜드마크 데이터가 필요하다.
랜드마크라길래 mediapipe로 구해버려야지 했지만,
6개 밖에 없는 랜드마크 데이터에, 뭘 기준으로 6개지 싶은 마음이 있었따.
다들 궁금했는지 그냥 issue에 input landmark만 검색해도 정보를 얻을 수 있었다.
https://github.com/sicxu/Deep3DFaceRecon_pytorch/issues/85
내가 저 글을 먼저 봤다면, 저걸로 했을텐데, DTCNN을 이용해 추정한다는 글만 보고 그냥 짜버렸다.
아래 코드는 datasets/test 경로의 모든 이미지의 랜드마크 데이터를 생성해준다.
generateData.py 라고 그냥 대강 이름 짓고
python generateData.py 실행하면 해당 경로의 이미지에 대해 추정 랜드마크를 인풋과 맞게 만들어준다.
import os
from mtcnn import MTCNN
import cv2
def get_all_image_paths(root):
"""폴더 내 모든 이미지 파일 경로 가져오기 (하위 디렉토리 포함)"""
image_paths = []
for dirpath, _, filenames in os.walk(root):
for file in filenames:
if file.lower().endswith(('png', 'jpg', 'jpeg')):
image_paths.append(os.path.join(dirpath, file))
return image_paths
def save_landmarks(lm_path, keypoints):
"""랜드마크를 .txt 파일로 저장"""
os.makedirs(os.path.dirname(lm_path), exist_ok=True)
with open(lm_path, 'w') as f:
for keypoint in keypoints:
f.write(f"{keypoint[0]:.1f}\t{keypoint[1]:.1f}\n")
def main(root='datasets/test'):
# 모든 이미지 파일 경로 가져오기
image_paths = get_all_image_paths(root)
detector = MTCNN()
for img_file in image_paths:
# 랜드마크 파일 경로 생성
lm_file = os.path.join(os.path.dirname(img_file), 'detections', os.path.splitext(os.path.basename(img_file))[0] + '.txt')
# 이미지 로드
image = cv2.imread(img_file)
if image is None:
print(f"Failed to load image: {img_file}")
continue
# 랜드마크 감지
faces = detector.detect_faces(image)
if not faces:
print(f"No faces detected in {img_file}")
continue
# 랜드마크 저장
keypoints = list(faces[0]['keypoints'].values())
save_landmarks(lm_file, keypoints)
print(f"Saved landmarks for: {img_file}")
if __name__ == '__main__':
main()
그리고 실행!
python test.py --name=shd --epoch=20 --img_folder=./datasets/test
| Input | Texture | Mesh |
 |
 |
 |
 |
 |
 |
 |
 |
 |
마스크는 모델의 문제가 아니라
내가 데이터 생성할 때 랜드마크가 잘못 잡힌 원인이 크다.
감긴 눈에 대해서도 처리를 한다 들어 감긴듯한 사진도 넣어보았다
다른 메쉬랑 비교해서 눈이 조금 작아 보이는 것 말고는 유사한 형채를 보였다.

아이유는 메쉬도 역시 참 예쁘게 나온다.
 |
 |
 |
텍스쳐 뽑기
는 아직 방법을 찾고있다.
아래처럼 blender에 python 코드를 넣어보기도 하고

https://github.com/sicxu/Deep3DFaceRecon_pytorch/issues/3
No output file · Issue #3 · sicxu/Deep3DFaceRecon_pytorch
(deep3d_pytorch) PS D:\Deep3DFaceRecon_pytorch> python test.py --name=CelebA --epoch=20 --img_folder=./datasets/examples D:\anaconda3\envs\deep3d_pytorch\lib\site-packages\kornia\augmentation\augme...
github.com
obj의 색상값과 mat에 정의된 텍스쳐 정보로 뽑아보고 있으나,
멋진 결과물은 뽑아보지 못했다...!
하지만 늘 그랬듯 곧 답을 찾을 것이라 믿고 있다!

'기술 단어장 > AI' 카테고리의 다른 글
| [Cohere] Cohere 기반 블로그 임베딩 & RAG 챗봇 구축 로직 (0) | 2025.10.18 |
|---|---|
| [Research] 나의 실감형 3D 얼굴 생성을 위한 연구 방향 (1) | 2025.01.16 |
| [AI] 3D 얼굴 생성을 위한 3D-GANTex 실행 과정 (1) | 2025.01.08 |
| [AI] 3D 얼굴 생성을 위한 Gaussian Head Avatar 코드 환경 설정 및 실행 (2) | 2024.12.09 |
| [NeRF] 3D 생성을 위한 동향 학습 (0) | 2024.11.05 |




댓글